







Hybrid Access to Semantic Data: Data Warehouses Meet Graph Databases
Written by Davide Chieregato
In the process of developing a suitable architecture, we have concluded that no single data technology can effectively cover all use cases, particularly regarding both scalability and semantic depth. Therefore, we rely on a hybrid approach, utilizing BigQuery for intuitive, powerful access to all stored data, and GraphDB/Neo4j for intricate relationship analysis and direct data visualization.
After presenting each of these two components, we will then detail our hybrid architecture and thoroughly compare it with a naïve single-store approach.
Introduction : Managing Data from Digitized Images
Our work on digitized images, which encompasses technical analysis, authentication analysis, and other related tasks, necessitates the management, querying, and visualization of a large volume of data. This data includes not only metadata, such as artist names, artwork titles, conservation locations, creation locations, and artistic movements, but also information extracted from the artworks using proprietary algorithms, such as color palette details. This rich dataset enables sophisticated semantic queries, such as finding the ten earliest paintings for each movement, identifying all artists whose artworks are conserved in their place of creation, or analyzing color palette trends over time, with the aim of visualizing the results. More generally, this hybrid model ensuring both scale and contextual insight proves especially powerful for domains such as cultural heritage, scientific imaging, or multimodal machine learning.
A Hybrid Data Storage Architecture
Data Warehouses
The first component of our architecture, and perhaps the most commonly used data storage technology, is the data warehouse. Data warehouses are optimized for running massive queries on materialized, structured datasets and are therefore ideal when fast and intuitive data access is needed.
In our specific case, querying millions of image-derived or aggregated features (color histograms, texture descriptors, edge maps, etc.) as well as operational and usage data (API usage logs, ingestion timestamps, and batch processing metadata useful for monitoring and cost analysis) becomes straightforward and high-performance. More concretely, access to data in BigQuery can be achieved in multiple ways: through direct SQL queries; by exposing views (subsets of the entire dataset that simplify complex logic); or via connectors that link the warehouse to visualization tools and dashboards. This flexibility makes it possible to move seamlessly from raw queries to interactive analytics experiences.
Graph Databases
Graph databases form the second component of our architecture. They excel not at bulk aggregation, but rather at exploring relationships and connectivity between entities, and at providing structured visualizations of how data points are related. In our case, this means linking together artworks, artists, and styles to form provenance chains and influence networks. For example, we can trace how a manuscript moved from a monastery to a private collector and then to a museum, and we can also incorporate visual features extracted from images. Data access in Neo4j is enabled through Cypher queries, which are designed to intuitively traverse nodes and relationships. In addition, graph-native visualization platforms such as GraphXR by Kineviz enhance the interpretability of these connections by transforming graph structures into 3D interactive visual representations. The use of connected data models is also demonstrated in NIST’s work on a knowledge-graph-based smart network repository, where information is organized in a comprehensive and extensible graph structure.
This relationship-focused model is reflected in Atlas visual data governance software, which connects objects, captures, observations, derived assets, and attestations through a time-aware graph while preserving end-to-end data lineage.
 QuantumSpace – Data Analysis – Neo4J
QuantumSpace – Data Analysis – Neo4J
A Hybrid Usage Framework
The true power of our data storage strategy is revealed when data warehouses and graph databases are viewed not as alternatives, but as complementary layers. Data is consolidated within the warehouse, enabling high-performance aggregations and time-series analytics, while relevant entities are projected into the knowledge graph for semantic exploration. This allows insights discovered in the graph (e.g., a cluster of stylistically connected artworks) to drive targeted queries within the data warehouse, and vice versa.
In addition, hybrid stacks are evolving beyond data warehouses and graph databases to include vector databases, which store multimodal embeddings, abstract representations in a high-dimensional space. These three layers, warehouses for scale, graphs for semantics, and vectors for similarity will likely define the future of digital pipelines, enabling the convergence of structured, relational, and semantic data.
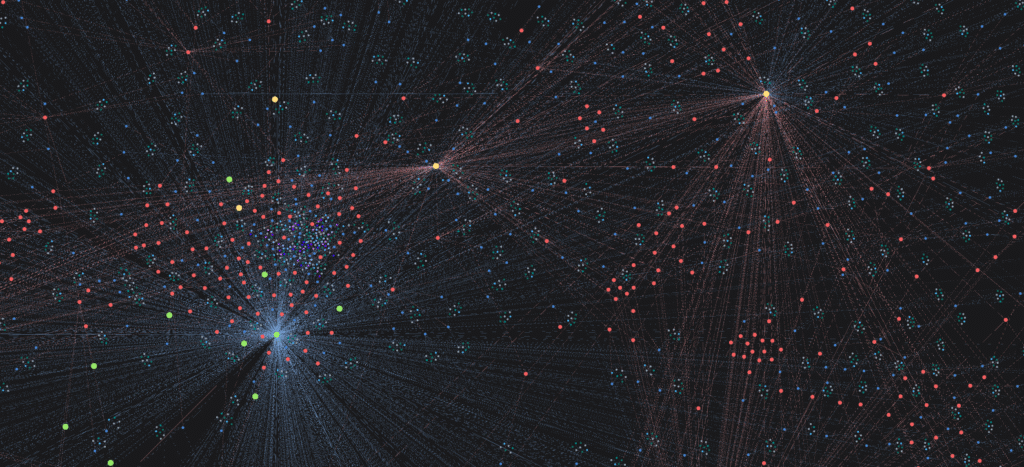 QuantumSpace – Data Correlations – Neo4J
QuantumSpace – Data Correlations – Neo4J
Evaluation of the Hybrid Strategy
Having presented our data storage strategy, we now benchmark it against a naïve single-store baseline using either a standalone data warehouse or a standalone graph database evaluated on three metrics: query response time, data preparation overhead, and maintenance cost.
Query Response Time
Regarding query response time, standalone data warehouses excel at large-scale aggregations (e.g., color distributions across five million artworks or average dimensions by century) but perform poorly on relationship traversals because they require costly recursive JOINs; conversely, graph databases handle multi-hop relationships efficiently but are less suited to heavy aggregations.
Our hybrid approach assigns aggregations and statistical queries to the warehouse and relationship-centric queries to the graph, making tasks such as identifying all artists influenced by Caravaggio and then computing the distribution of materials they used feasible within practical time bounds.
Data Preparation Overhead
Concerning data preparation overhead, a DW-only approach demands a well-defined schema and robust ETL (Extract, Transform, Load) to normalize metadata, whereas a graph-only approach focuses on explicit relationship modeling and imports with looser schema enforcement. A hybrid approach adds integration work by loading the warehouse and exporting to the graph, yet it maximizes flexibility, for example keeping metadata in BigQuery while modeling influence networks in Neo4j.
Maintenance Cost
Finally, regarding maintenance cost, data warehouses typically provide mature tooling and predictable scaling that lower operational overhead, but they limit flexibility for evolving relationship-heavy use cases. Graph systems offer flexible relationship modeling but often require specialized expertise and careful tuning for aggregation workloads; a hybrid contains costs by letting each engine do what it does best while adding integration surfaces to monitor and maintain.
 QuantumSpace – Data Architecture – Neo4J
QuantumSpace – Data Architecture – Neo4J
Conclusion
In conclusion, our hybrid data storage strategy combines data warehouses for scale and intuitive access with graph databases for semantic exploration, enabling fast query response time, manageable data preparation overhead, and contained maintenance cost. By consolidating metadata and image‑derived features in BigQuery and projecting entities into Neo4j or GraphDB for relationship analysis and visualization, we ensure both scalability and semantic depth; as vector databases mature, this complementary stack will further enhance multimodal querying and interactive analytics across structured, relational, and semantic data.
Related Posts:
From Subjectivity to Precision: Removing Inconsistency in Medical Evaluations
QLens establishes the foundations for a global medical infrastructure capable of tracking pathogenesis in real time, providing structural support while leaving the clinical interpretation to the physicians.

Our Solution to Review, Preserve and Enhance Artworks: Muse
The presentation of Muse, a complete and optimised proprietary system designed to assist museums, curators and institutions in the analysis and review of artworks, in a scientific and structured fashion.
Fatigue and Performance Diagnosis: The QLens Solution
QLens establishes the foundations for a global medical infrastructure capable of tracking pathogenesis in real time, providing structural support while leaving the clinical interpretation to the physicians.